故障模拟与自动恢复
作为一个开源数据管理平台,KubeBlocks 目前支持三十多种数据库引擎,并且持续扩展中。由于这些数据库本身的高可用能力是参差不齐的,因此 KubeBlocks 设计实现了一套高可用系统用于保障数据库实例的高可用能力。KubeBlocks 高可用系统采用了统一的HA框架设计,实现对数据库的高可用支持,使得不同的数据库在 KubeBlocks 上可以获得类似的高可用能力和体验。
下面以 MySQL 社区版为例,演示它的故障模拟和恢复能力。
故障恢复
下面通过删除 Pod 来模拟故障。在资源充足的情况下,也可以通过机器宕机或删除容器来模拟故障,其自动恢复过程与本文描述的相同。
开始之前
-
创建 MySQL 主备版集群,详情可参考 创建 MySQL 集群。
-
执行
kubectl get cd mysql -o yaml检查 MySQL 集群版是否已启用 rolechangedprobe(默认情况下是启用的)。如果出现以下配置信息,则表明已启用:probes:
roleProbe:
failureThreshold: 2
periodSeconds: 1
timeoutSeconds: 1
主节点异常
步骤:
- kubectl
- kbcli
-
查看 MySQL 主备版 pod 角色。在本示例中,主节点为
mycluster-mysql-0。kubectl get pods --show-labels -n demo | grep role
-
删除主节点
mycluster-mysql-0,模拟节点故障。kubectl delete pod mycluster-mysql-0 -n demo
-
检查 pod 状态和集群连接。
此处示例显示 pod 角色发生变化。原主节点删除后,系统选出新的主节点为
mycluster-mysql-1。kubectl get pods --show-labels -n demo | grep role
-
查看集群信息。可在
Topology中查看主节点的名称,在如下例子中,主节点为mycluster-mysql-0。kbcli cluster describe mycluster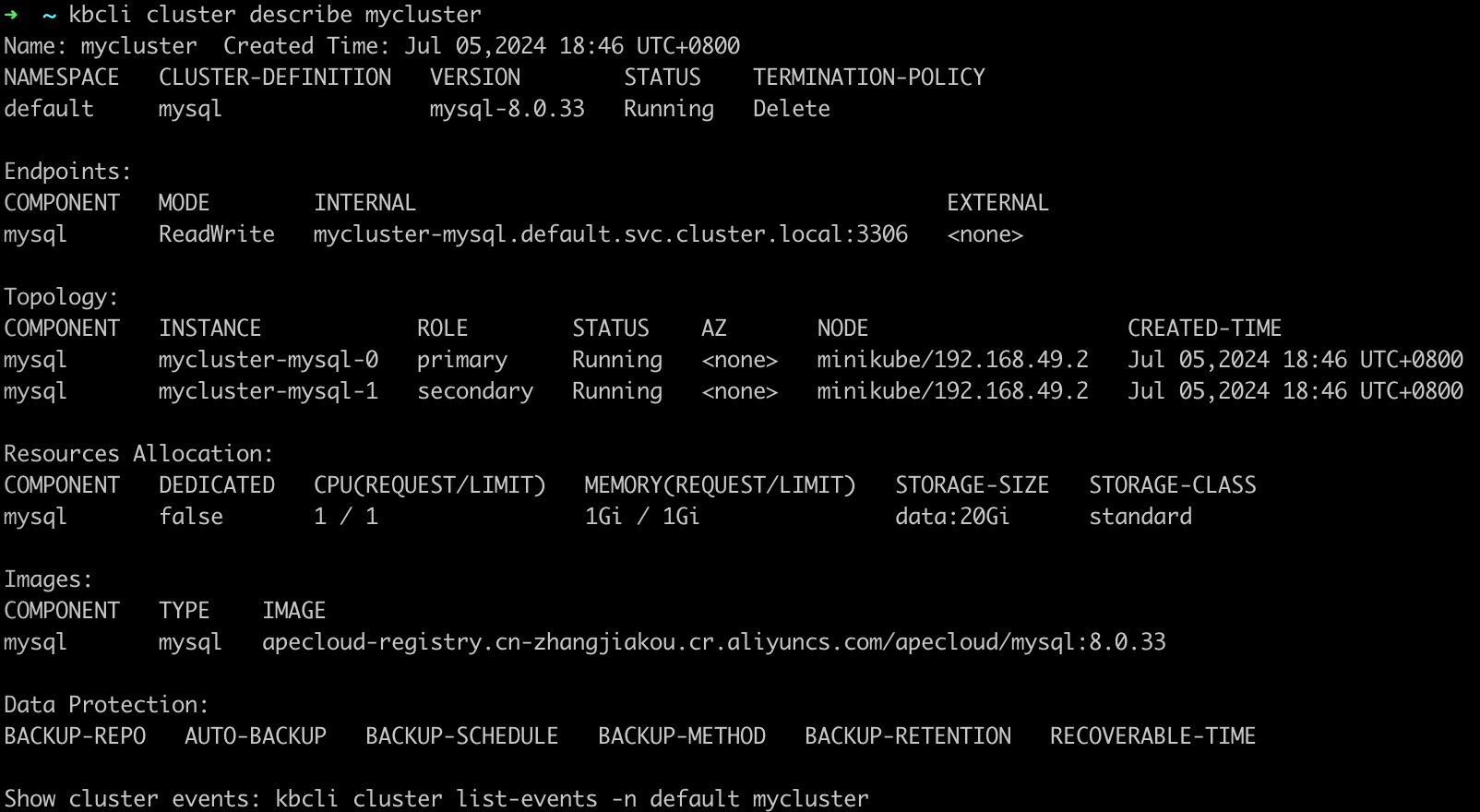
-
删除主节点
mycluster-mysql-0,模拟节点故障。kubectl delete pod mycluster-mysql-0
-
执行命令,查看 pod 状态和集群连接。
Results
此处示例显示 pod 角色发生变化。原主节点删除后,系统选出新的主节点为
mycluster-mysql-1。kbcli cluster describe mycluster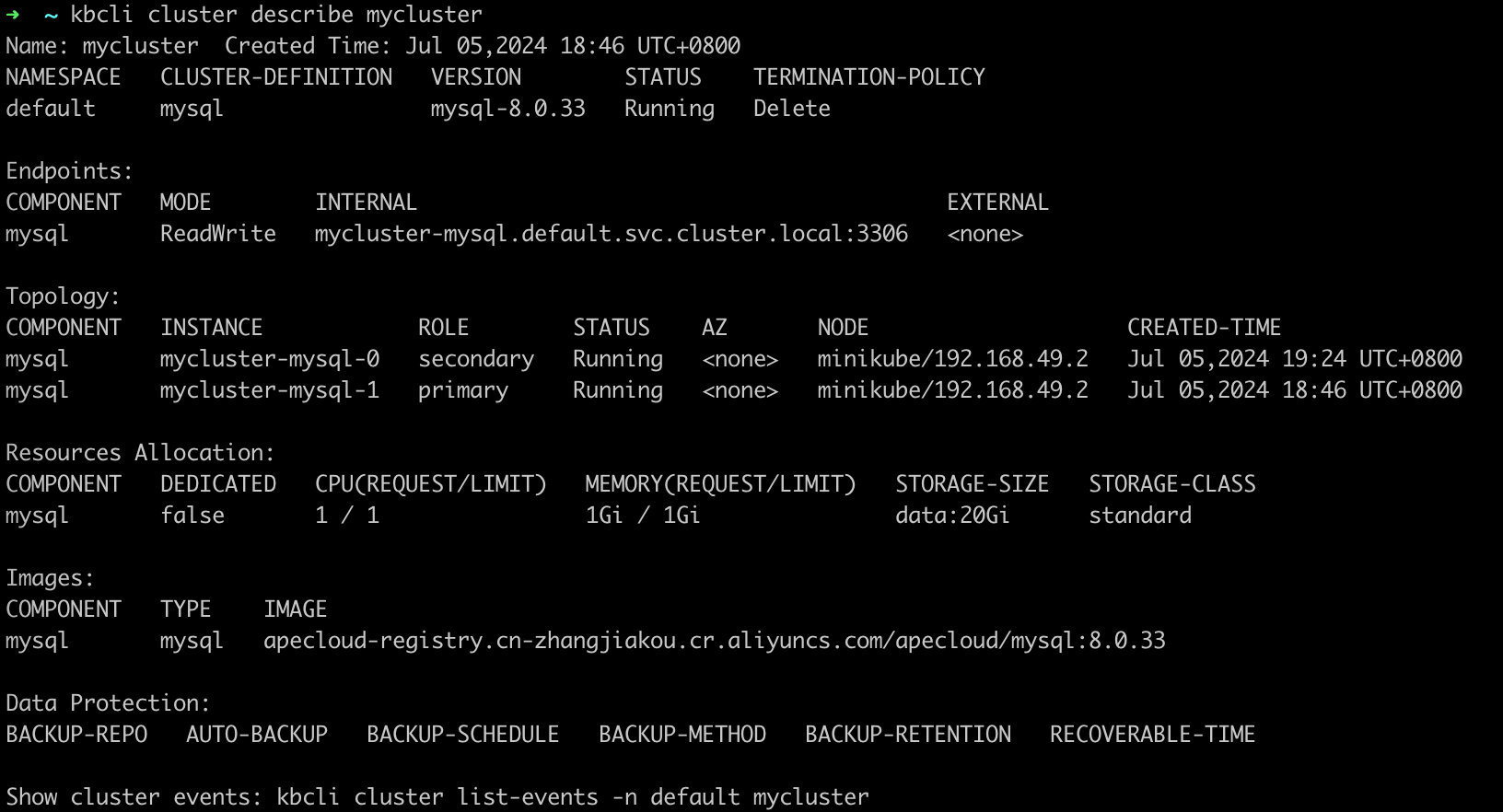
MySQL 主备版集群可在几秒钟连接。
自动恢复机制
主节点删除后,MySQL 主备版会自行选主。上述示例中,选出新的主节点为 mycluster-mysql-1,KubeBlocks 探测到主节点角色发生变化,会发出通知,更新访问链路。原先异常节点会自动重建,恢复正常集群版状态。从异常开始到恢复完成,整体耗时正常在 30s 之内。
备节点异常
步骤:
- kubectl
- kbcli
-
查看 pod 角色,如下示例中备节点为
mycluster-mysql-0。kubectl get pods --show-labels -n demo | grep role
-
删除备节点
mycluster-mysql-0。kubectl delete pod mycluster-mysql-0 -n demo
-
打开一个新的终端窗口,查看 pod 状态。可以发现备节点
mycluster-mysql-0处于Terminating状态。kubectl get pod -n demo
再次查看 pod 角色。

-
查看集群信息。可在
Topology中查看备节点的名称,在��如下例子中,备节点为mycluster-mysql-0。kbcli cluster describe mycluster -
删除备节点
mycluster-mysql-0。kubectl delete pod mycluster-mysql-0
-
查看集群状态,可在
Component.Instance看到备节点处于终止状态。kbcli cluster describe mycluster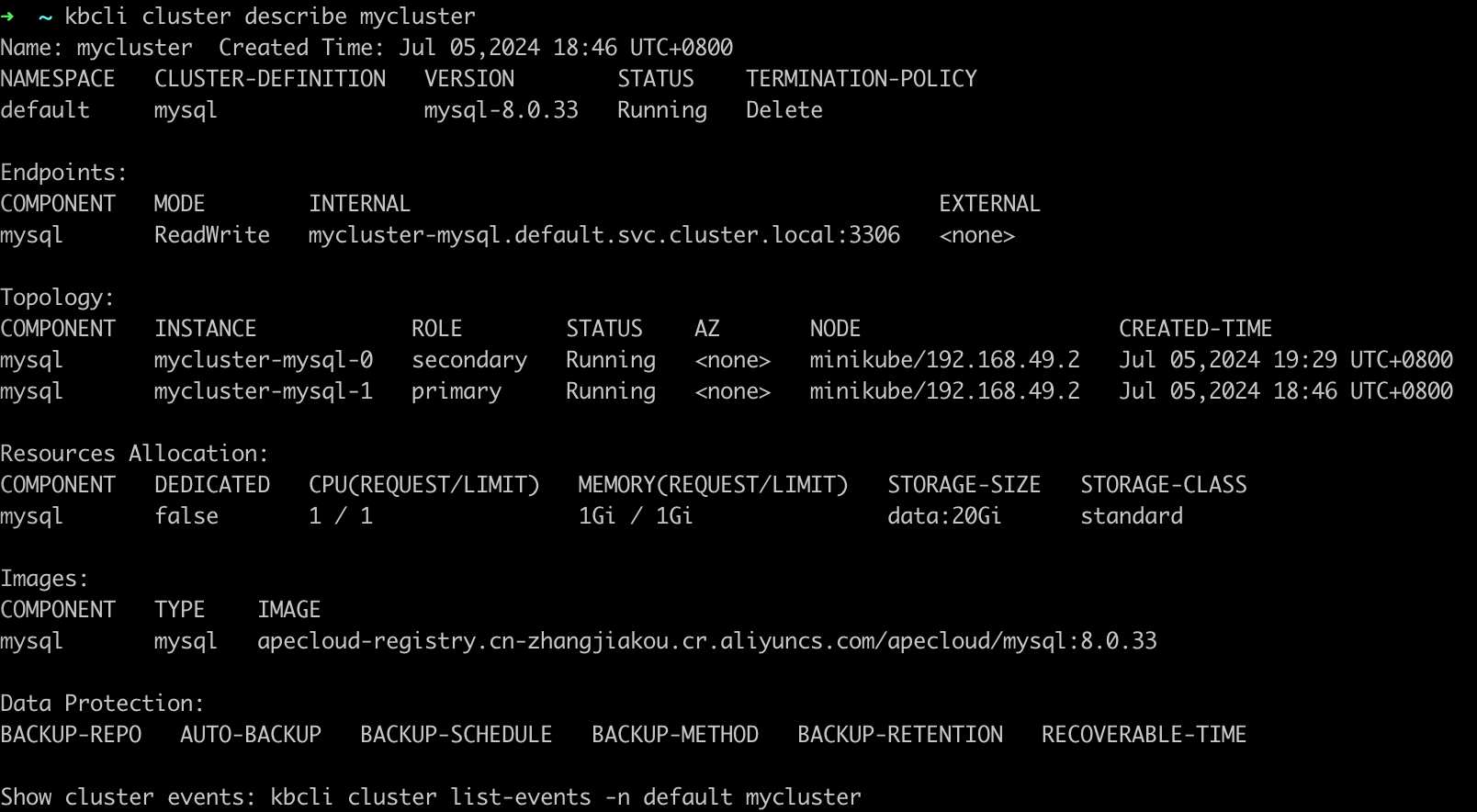
自动恢复��机制
单个备节点异常不会触发角色重新选主,也不会切换访问链路,所以集群读写不受影响,备节点异常后会自动触发重建,恢复正常,整体耗时正常 30s 之内。
两个节点异常
步骤:
- kubectl
- kbcli
-
查看 pod 角色。
kubectl get pods --show-labels -n demo | grep role
-
删除所有 pod。
kubectl delete pod mycluster-mysql-0 mycluster-mysql-1 -n demo
-
打开一个新的终端窗口,查看 pod 状态,发现所有 pod 均处于
Terminating状态。kubectl get pod -n demo
-
再次查看节点角色,发现已选举产生新的主节点。
kubectl get pods --show-labels -n demo | grep role
-
查看集群信息,在
Topology中查看节点名称。kbcli cluster describe mycluster -
删除所有节点。
kubectl delete pod mycluster-mysql-1 mycluster-mysql-0
-
查看删除任务进展,发现所有节点都处于 pending 状态,几秒后恢复正常。
kbcli cluster describe mycluster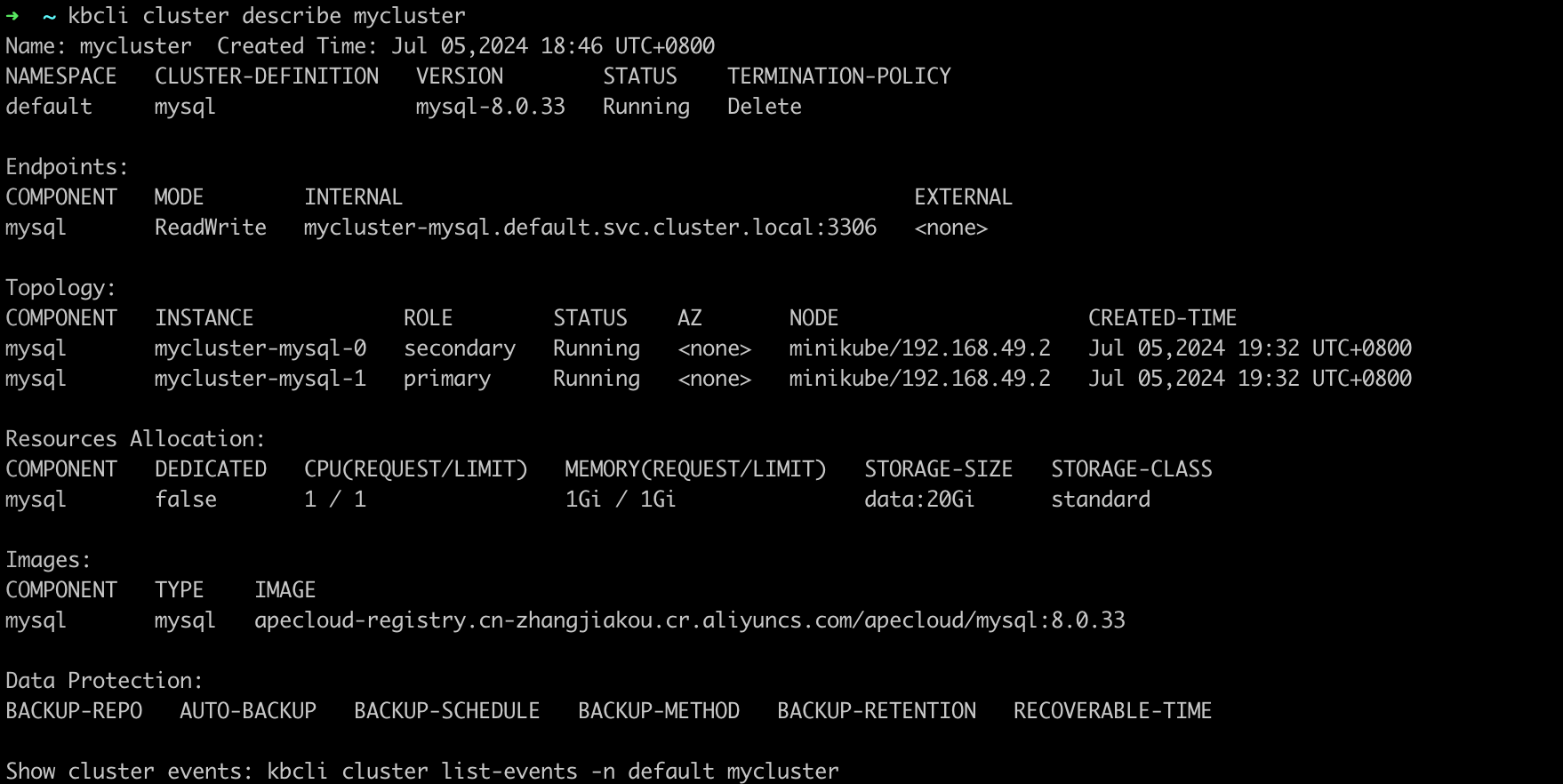
自动恢复机制
这是因为节点删除后,都会自动触发重建,然后 MySQL 会自动完成集群恢复及选主。选主完成后,KubeBlocks 会探测新的主节点,并更新访问链路,恢复可用。整体耗时在 30 秒内。